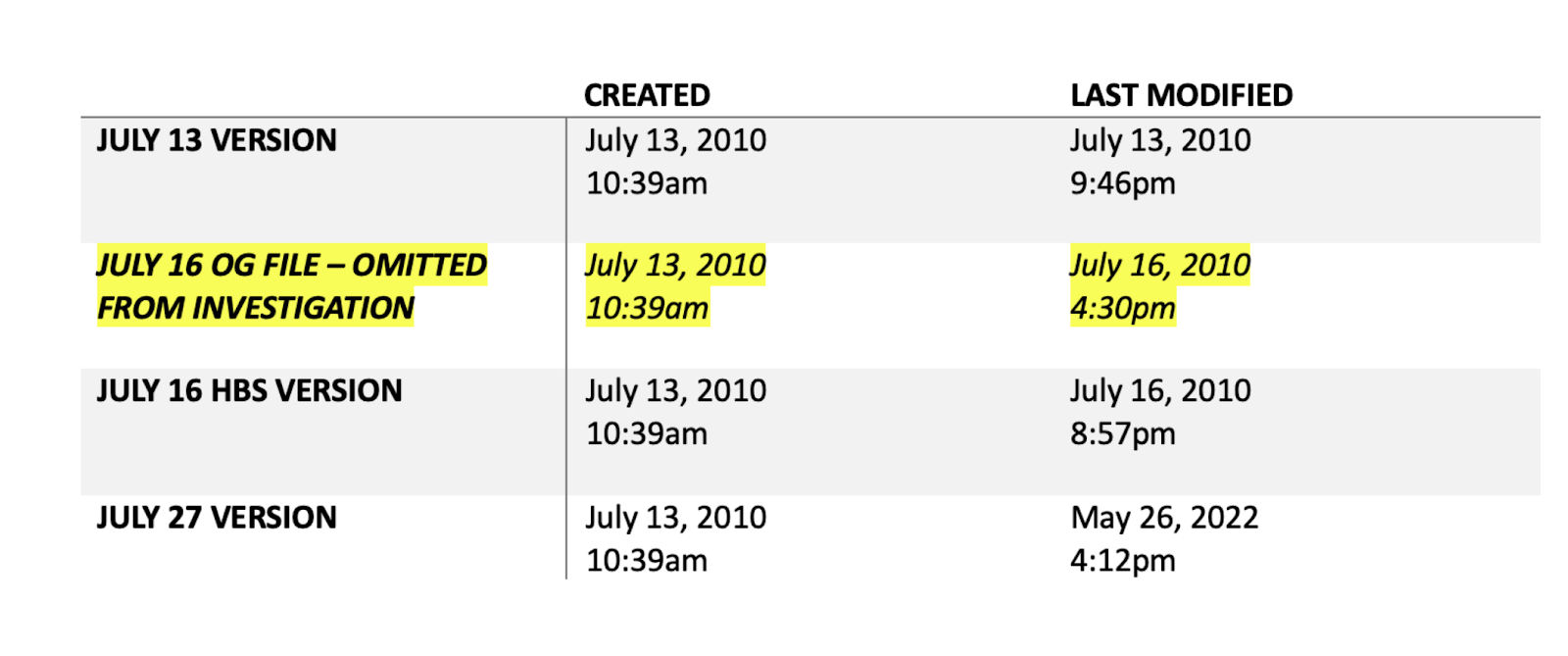
A new look, but the same content as the Replicability-Index blog. The reason for the change is that WordPress is no longer working for me. The first post here continues the Gino-Colada series that critically examines Gino's blog defense of her research practices to support her claim that she never falsified data. Gino-Colada 1 Gino-Colada 2 In her third blog post , she takes aim at the investigation of her work by Harvard Business School. The key issue is that there are several datafiles and that discrepancies between these datafiles may suggest tempering with the data. Gino claims that discrepancies can be easily explained by common practices of data cleaning. One lesson to take away from this mess is to have good data management practices in your lab. This is easier since most data are recorded automatically. Personally, I suggest to never alter the raw data file and to exclude participants or change values using syntax to make clear what rules wer...