A new look, but the same content as the Replicability-Index blog. The reason for the change is that WordPress is no longer working for me.
The first post here continues the Gino-Colada series that critically examines Gino's blog defense of her research practices to support her claim that she never falsified data.
In her third blog post, she takes aim at the investigation of her work by Harvard Business School.
The key issue is that there are several datafiles and that discrepancies between these datafiles may suggest tempering with the data. Gino claims that discrepancies can be easily explained by common practices of data cleaning.
One lesson to take away from this mess is to have good data management practices in your lab. This is easier since most data are recorded automatically. Personally, I suggest to never alter the raw data file and to exclude participants or change values using syntax to make clear what rules were used and to allow for reproducibility. However, we cannot go back in time and Gino's lab did have multiple datafiles with different entries.
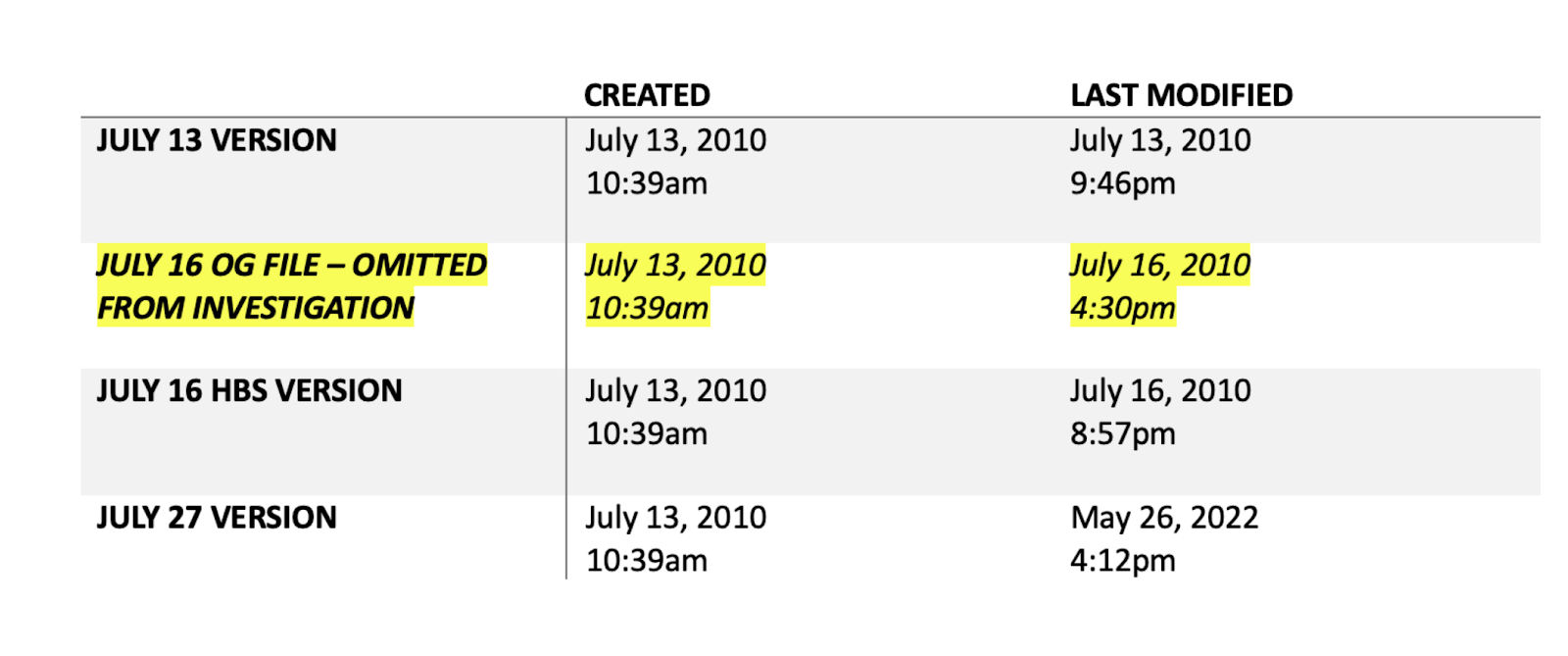
Gino explains that the July 13 datafiles is incomplete because more data were collected until July 27 when the last datafile was created. However, some data are different or missing.
"The July 16 OG file contains all the data from the July 13 file, except for some data that appears to have been discarded or corrected. Why was any data discarded or corrected?"
I don't have access to the earlier datafiles, but I have been working with the last datafile that was posted on OSF. The simple observation that I want to share here is that one column in this datafile records participant numbers. Presumably, these numbers are assigned to participants as they enter the study. It is also clear that they are independent of conditions because the datafile is sorted by conditions first and participant numbers second. The first participants in condition 0 are 2,3, 10, in condition 1 they are 1, 4, 6 and in condition 2 they are 5, 8, 13 (ignoring the controversial rows that DataColada flagged as potentially fraudulent).
One side issue is that it is not clear to me how participants were assigned to conditions. One might expect that participant 1 is assigned to condition 0, participant 2 is assigned to condition 1, and participant 3 is assigned to condition 2 and so on to assure equal numbers of participants in the three conditions. However, when the datafile is sorted by participant numbers the sequence of conditions is
1, 0, 0, 1, 2, 1, 2, 2, 1, 0, 1, 1, 0 ....
Maybe assignment was random, leading to slightly unequal sample sizes for the three conditions among the first 50 participants (n = 15, n = 19, n = 16). As I said, this is a side issue.
The notable observation is that the participant numbers for the first 50 participants are integers from 1 to 49. The reason that it is not 50 is that there are two rows with the participant number 13.
I was surprised to see that there are no missing participant numbers if participants had been deleted from the July 13 datafile that included the first 50 participants. The explain the fact that there are no missing participant numbers that correspond to deleted participants, Gino would have to argue that these numbers were used later on for new participants to make up for the missing ones, but I would say that is unusual. Another explanation could be that the numbers in the p-columns are not actual participant numbers, but it is not clear why these numbers were added later and mistakes were made in entering number 13 twice.
The full sequence for the 101 rows is: 1...13,13,14...49,49,50...97,100,101
So, the missing participant numbers are 98,99. It is rather odd that two participants with unusable data would have consecutive participant numbers. Clearly, they are not among the first 50 participants that were presumably included in the July 13 data file. I don't see how participant numbers 98 and 99 would show up in a file that contains the data of the first 50 participants.
I don't have access to a lot of information that the Harvard Business School investigators or DataColada have. I am just trying to make sense of Gino's defense of accusations against data fabrication. Each of her blog posts makes a compelling argument, but when I look a bit into the data, I have doubts that her arguments are consistent with the evidence. It will probably take years till we get all the facts. Until then, it is probably best to ignore this scandal that is just a distraction from all the bigger problems that undermine the credibility of behavioral sciences in business schools and psychology departments. Fraud is just an attention grabbing tip of the iceberg of questionable practices that allows social scientists to sell their opinions and beliefs as facts because they found a way to get p < .05 in a few studies.
In conclusion, if participants were deleted for legitimate reasons after the first 50 participants were collected, I would expect some missing participant numbers among the first 50 participants. However, the open datafile shows the number 13 twice and has no missing numbers from 1 to 49.
Comments
Post a Comment